Project Overview
Project overview | Using the portal | REST API | Data organization | Data submission | Encyclopedia
About the ENCODE Consortium
The Encyclopedia of DNA Elements (ENCODE) Consortium is an ongoing international collaboration of research groups funded by the National Human Genome Research Institute (NHGRI). The goal of ENCODE is to build a comprehensive parts list of functional elements in the human genome, including elements that act at the protein and RNA levels, and regulatory elements that control cells and circumstances in which a gene is active.
ENCODE investigators employ a variety of assays and methods to identify functional elements. The discovery and annotation of gene elements is accomplished primarily by sequencing a diverse range of RNA sources, comparative genomics, integrative bioinformatic methods, and human curation. Regulatory elements are typically investigated through DNA hypersensitivity assays, assays of DNA methylation, and immunoprecipitation (IP) of proteins that interact with DNA and RNA, i.e., modified histones, transcription factors, chromatin regulators, and RNA-binding proteins, followed by sequencing.
Current ENCODE Consortium Participants and Projects
The current ENCODE Consortium (ENCODE 4) is composed primarily of scientists funded under Requests for Application (RFAs) released by NHGRI in 2011. NHGRI provides a list of current ENCODE projects and participants. The ENCODE External Consultants Panel oversees the activities of the Consortium and provides advice and feedback on the Consortium's goals, progress and membership.
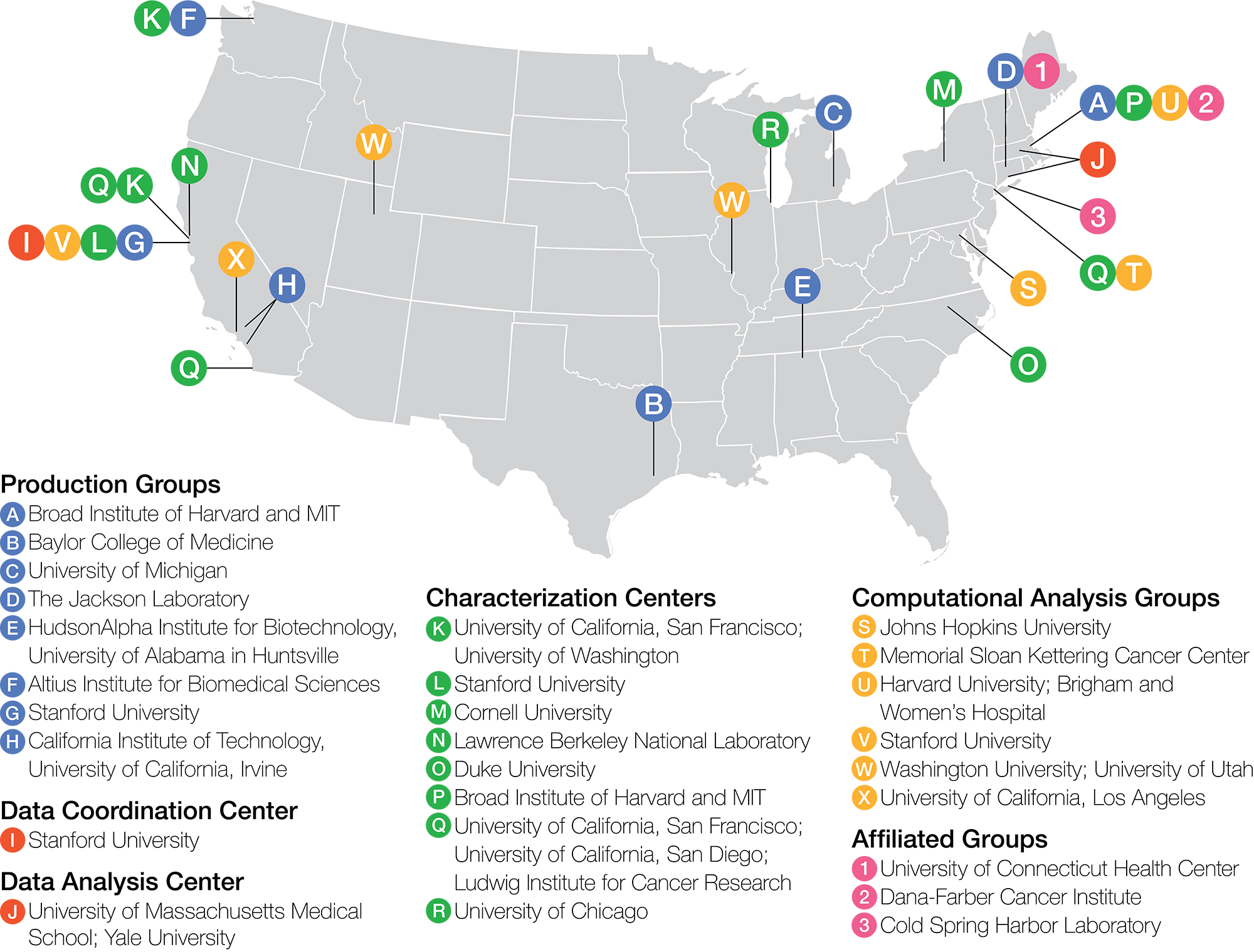
The consortium is open to any investigator willing to abide by the criteria for participation established for the ENCODE Project by NHGRI and has brought in additional participants when appropriate. Those interested in applying for membership to the ENCODE Consortium should review the ENCODE Project criteria for participation and contact the ENCODE program directors at NHGRI, Elise Feingold, Ph.D., Mike Pazin, Ph.D., Daniel Gilchrist, Ph.D, or Stephanie A. Morris, Ph.D.
Previous Consortium Participants and Projects
In September 2003, the NHGRI introduced the ENCODE project to facilitate the identification and analysis of the complete set of functional elements in the human genome sequence. During the initial pilot and technology development phases of the project, 44 regions—approximately 1% of the human genome—were targeted for analysis using a variety of experimental and computational methods with the aim of assembling a comprehensive encyclopedia of the functional elements in these regions, showing their identity and precise location. The pilot project established protocols for scaling up to full-genome coverage and produced a wealth of data, elucidating elements such as protein-coding genes, transcription units, protein binding sites, conserved DNA elements, features of chromatin assembly and modification, and single nucleotide polymorphisms.
The data generated by projects and participants in the pilot phase were submitted, processed, and released by the UCSC Genome Browser. The data from the pilot phase are still accessible from the pilot phase repository at UCSC.
The production scale-effort of the ENCODE project began in 2007. The data generated by projects and participants in the production scale were submitted, processed, and released by the UCSC Genome Browser. Data from the previous production scale-effort phases (ENCODE 2 and ENCODE 3) are also available from the Portal.
All data generated by the ENCODE Consortium is also available on this site and can be easily browsed and searched. Details of data organization and release prior to 2014 are found at the UCSC Genome Browser ENCODE data release log.