ENCODE Encyclopedia, Version 1: Genomic annotations
Introduction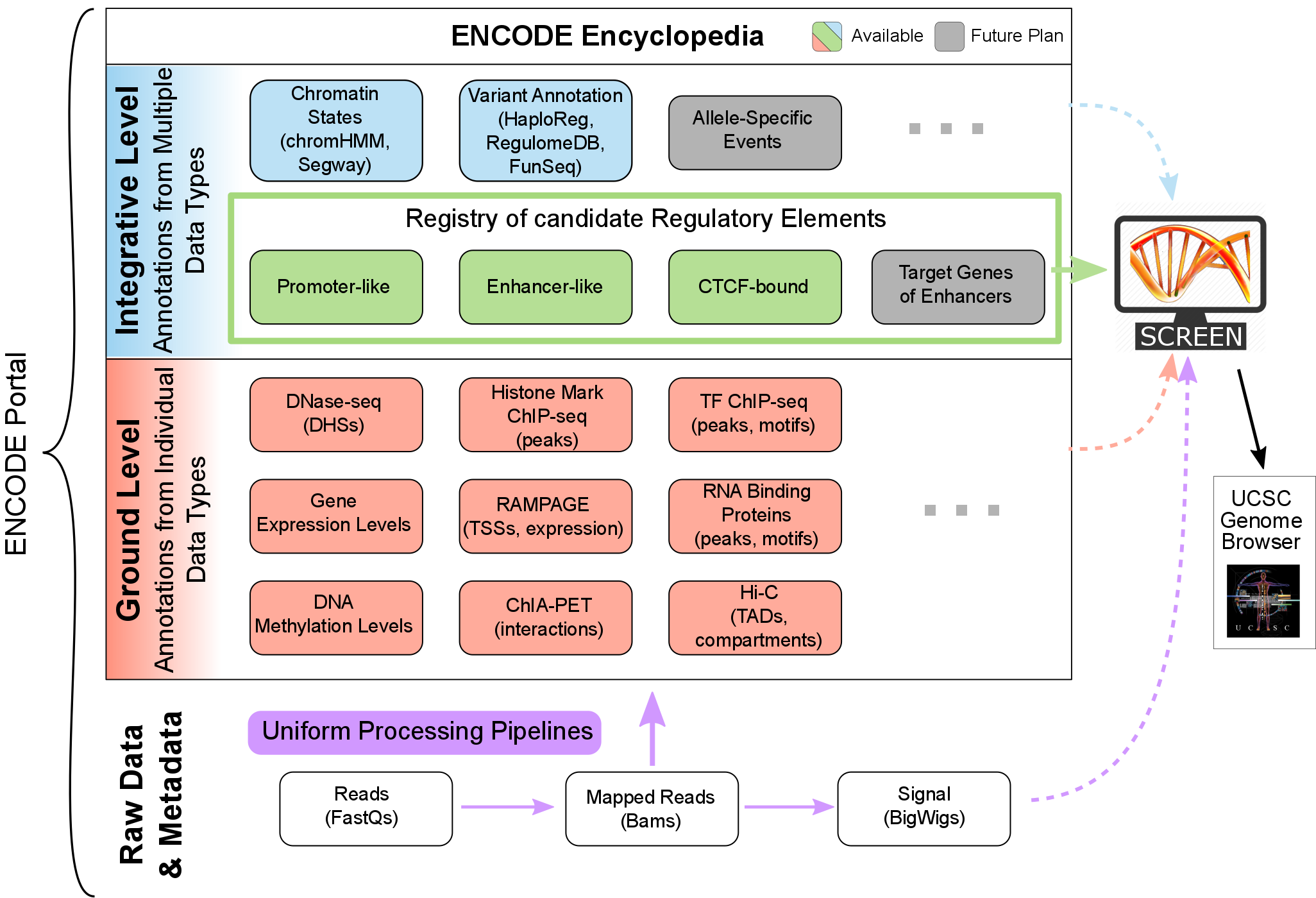
The ENCODE Consortium not only produces high-quality data, but also analyzes the data in an integrative fashion. The ENCODE Encyclopedia organizes the most salient analysis products into annotations, and provides tools to search and visualize them. The Encyclopedia has two levels of annotations:
- Ground-level annotations are derived directly from the experimental data, typically produced by uniform processing pipelines.
- Integrative-level annotations integrate multiple types of experimental data and ground level annotations.
Ground Level Annotations
Open chromatin (DNase-seq, ATAC-seq)DNase I hypersensitive sites (DHSs) computed from DNase-seq experiments, and ATAC-seq peaks (enriched genomic regions). |
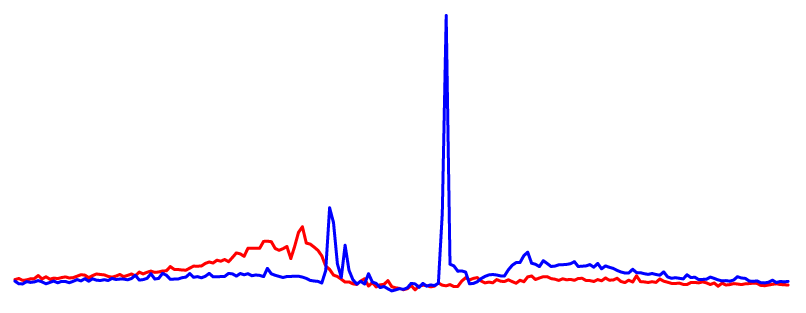 CTCF DHS Profile |
Histone mark enrichment (ChIP-seq)Peaks (enriched genomic regions) of a variety of histone marks computed from ChIP-seq experiments. |
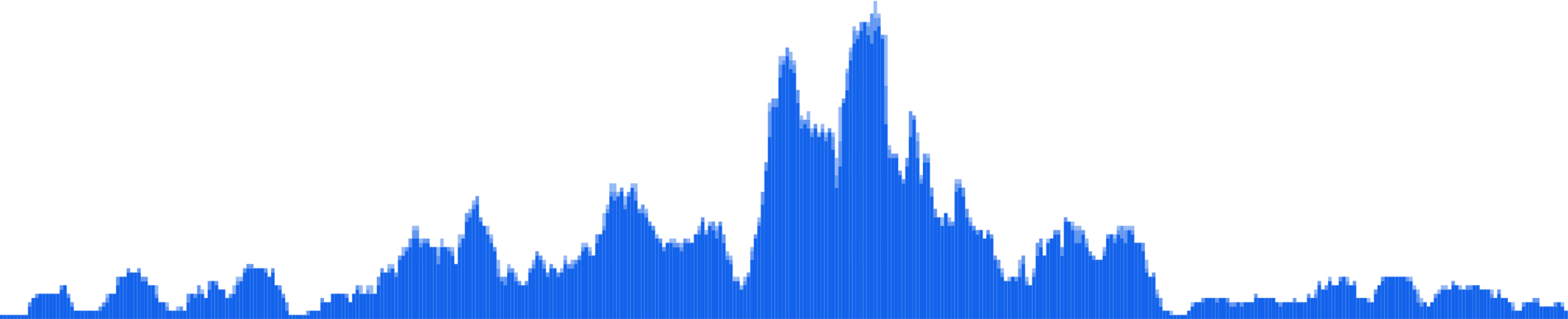 H3K27ac from e11.5 Neural Tube |
Transcription factor binding (TF ChIP-seq)Peaks (enriched genomic regions) of TFs computed from ChIP-seq experiments.Visualize sequence motifs and other information [ Factorbook ] |
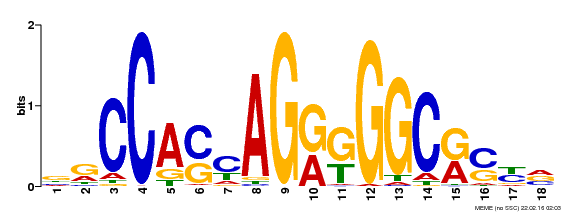 CTCF Motif from Factorbook
|
Gene expression (RNA-seq)Expression levels of genes and transcripts annotated by GENCODE.[ SCREEN | Yue Lab Browser | Method ] |
 BRCA1 Gene Expression |
Promoter activity profiling (RAMPAGE)Quantification of gene expression and identification of promoter locations. |  RAMPAGE data signal at EP300 |
RNA binding protein occupancy (eCLIP-seq)Peaks (enriched genomic regions) computed from eCLIP-seq data in human cell lines K562 and HepG2 for RNA Binding Proteins (RBPs). | 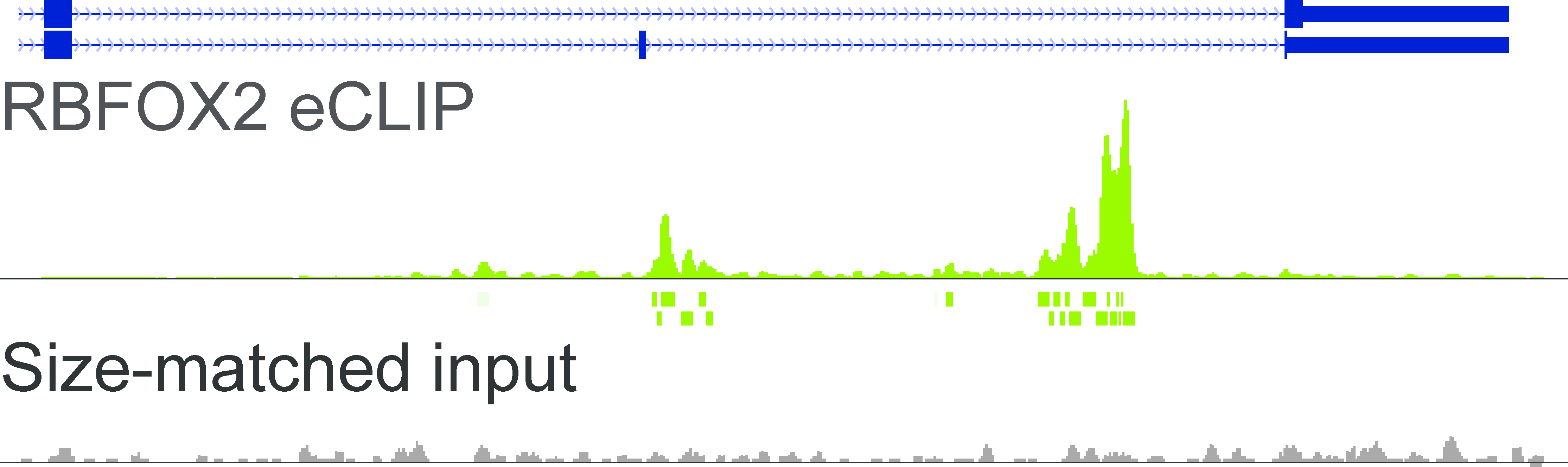 RBFOX2 read density |
DNA methylation (RRBS, WGBS)Genome-wide methylation state of CpG dinucleotides.[ Download ] |
 RRBS analysis in GM12878 |
Three dimensional chromatin interactions (ChIA-PET)3D interactions between genomic loci such as promoters and distal enhancers computed from ChIA-PET experiments. |
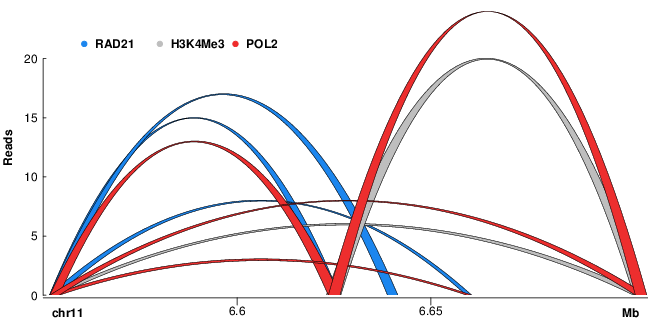 ChIA-PET interactions |
Topologically associating domains (TADs) (Hi-C)TADs and A and B compartments computed from Hi-C experiments.[ Visualize ] |
 K562 Interaction Matrix |
Integrative Level Annotations
The Registry of Candidate Regulatory ElementsThe core of the integrative level of the ENCODE Encyclopedia is the Registry of candidate Regulatory Elements (cREs), which integrates all high-quality DNase-seq and H3K4me3, H3K27ac, and CTCF ChIP-seq data produced by the ENCODE and Roadmap Epigenomics Consortia. The cREs in the Registry are the subset of representative DNase hypersensitivity sites (rDHSs) that are supported by these two histone modifications and CTCF-binding data. Currently the Registry (version 1) contains 1,310,152 human cREs and 527,001 mouse cREs. Using H3K4me3, H3K27ac, and CTCF signals across all cell types, we classified cREs into promoter-like, enhancer-like, CTCF-bound insulator-like groups in a cell-type agnostic manner. For each specific cell type, we also classified cREs into these groups using DNase, H3K4me3, H3K27ac, and CTCF data specific for that cell type. Currently 21 human (11 mouse) cell types have complete cell-type-specific cRE classifications and 598 human (117 mouse) cell types have partial cRE classifications. |
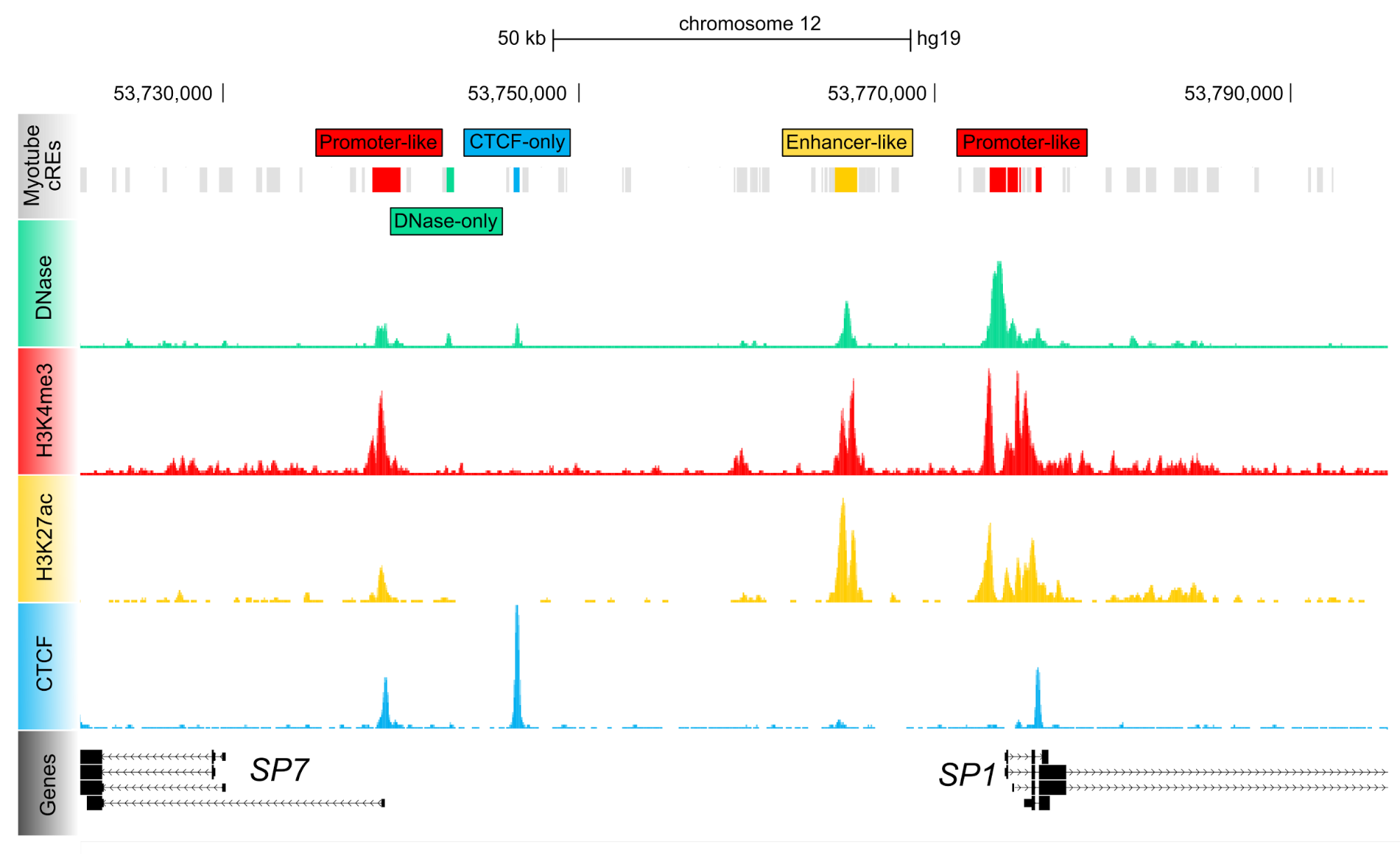 |
SCREENSCREEN is a web-based search and visualization engine specifically designed for the Registry of cREs. SCREEN allows users to explore cREs and investigate how they connect with other annotations in the Encyclopedia in a cell-type-specific manner, as well as the underlying raw ENCODE data whenever informative. SCREEN also presents the results of using cREs to interpret the variants uncovered by Genome-wide Association Studies (GWAS). |
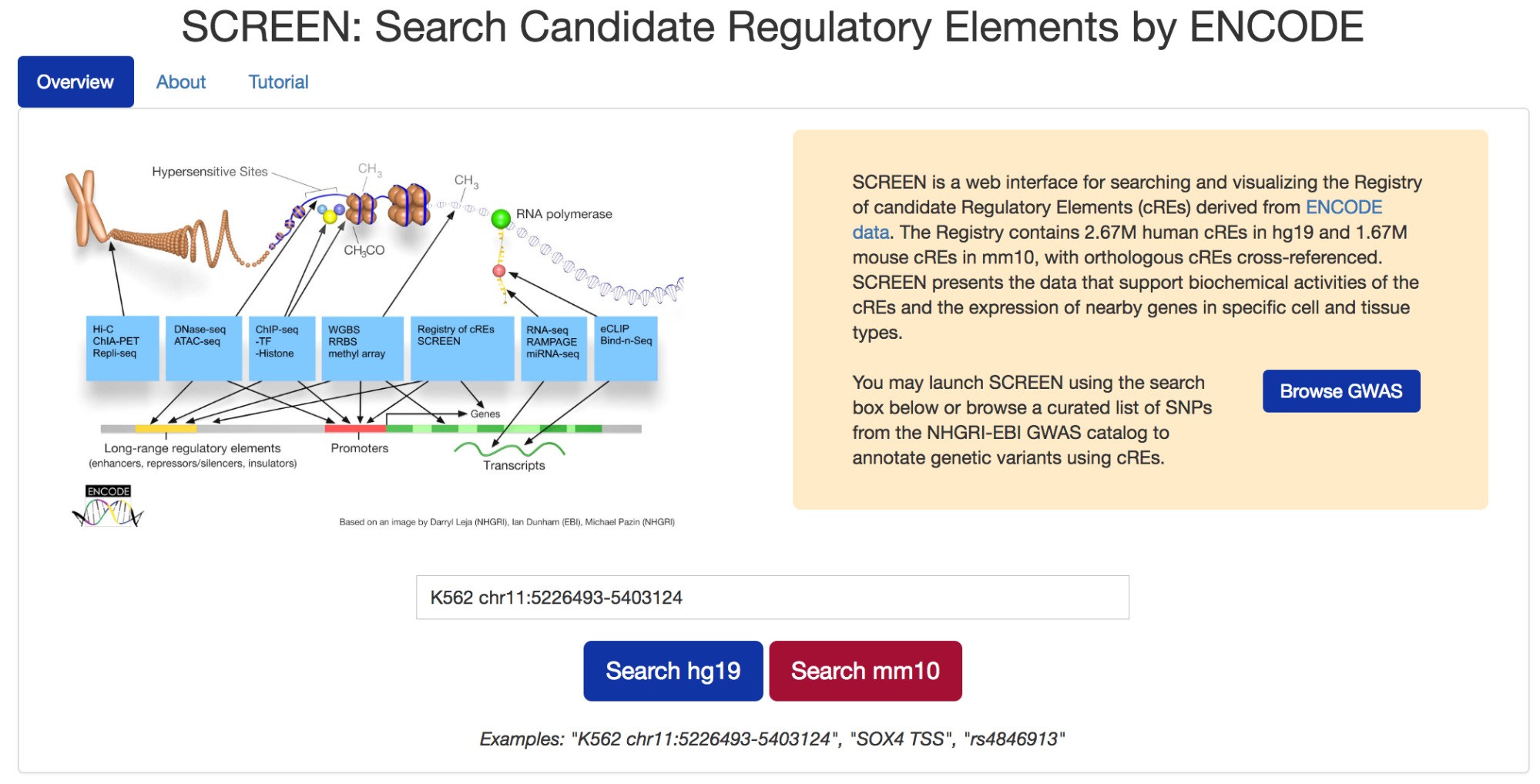 |
Chromatin statesSemi-automated genomic annotation methods such as ChromHMM and Segway take as input a panel of epigenomic data (including histone mark ChIP-seq and DNase-seq) in a particular cell type and use machine learning methods to simultaneously partition the genome into segments and assign chromatin states to these segments; the states are assigned such that two segments with the same state exhibit similar epigenomic patterns. The procedure is "semi-automated" because states are then manually compared with known biological information in order to designate each state as an enhancer-like, promoter-like, gene body, etc. The chromatin states of 164 human cell types have been annotated using this strategy by integrating 1,615 genomics datasets (Libbrecht et al., bioRxiv 086025). The chromatin states for mouse epigenomes of 12 tissue types at 8 different developmental timepoints, constituting 66 epigenomes of 8 histone marks each, have been annotated using a model integrating 1,056 genomic datasets and their respective controls. |
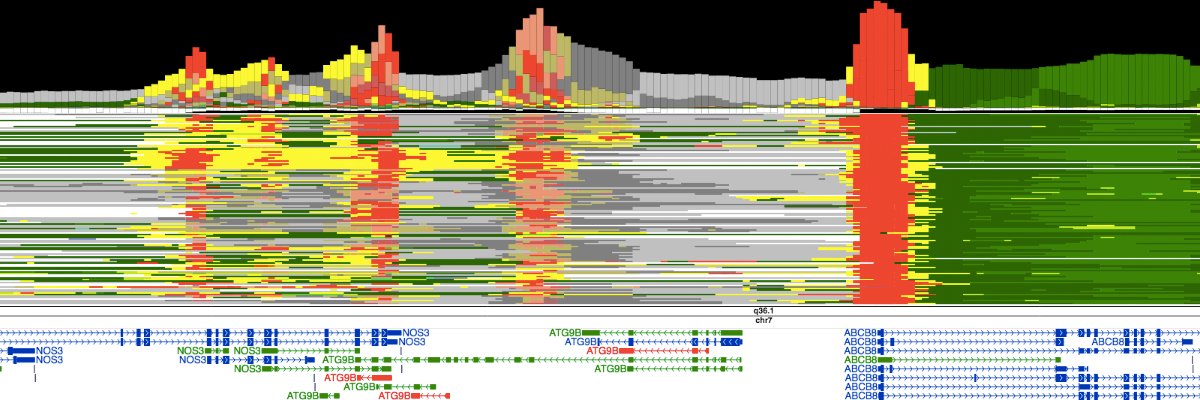
|
Variant AnnotationOver the past decade, Genome Wide Association Studies (GWAS) have provided insights into how genetic variations contribute to human diseases. However, over 80% of the variants reported by GWAS are in noncoding regions of the genome and the mechanism of how they contribute to disease onset is unknown. By integrating data from the ENCODE project and other public sources, RegulomeDB and HaploReg are two resources developed by ENCODE labs to aid the research community in annotating GWAS variants. FunSeq is another ENCODE resource for annotating both germline and somatic variants, particularly in the noncoding regions of cancer genomes. |
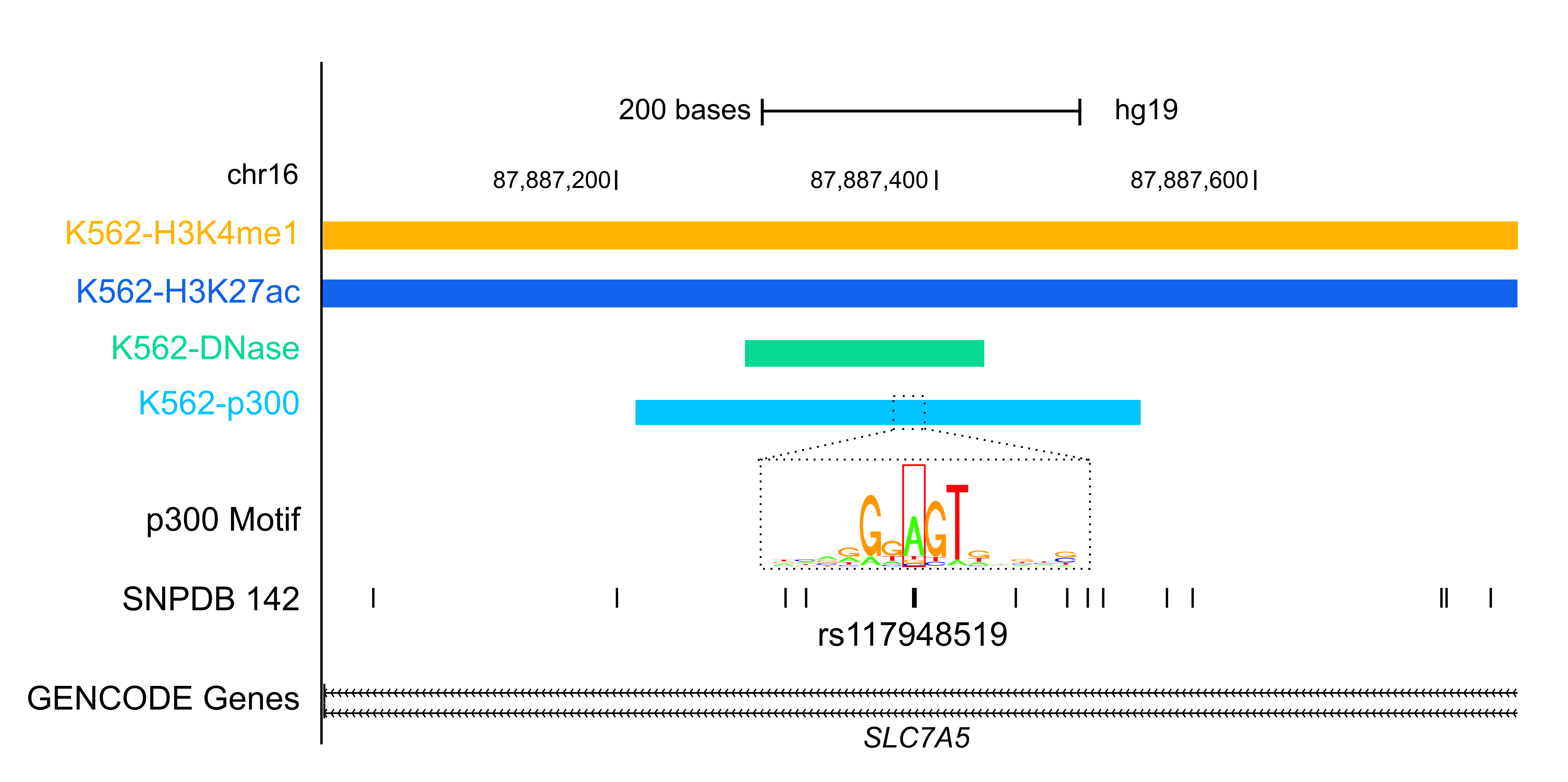 |
Acknowledgements
Data from the Common fund supported Roadmap Epigenomics Mapping Consortium (REMC) were included for building the ENCODE Encyclopedia. Please see the 2015 paper on their analysis of reference human genomes for more information.